
I decided to try out this lossless text-compression demonstration site by Fabrice Bellard. It uses GPT-2 natural language generation and prediction to achieve compression. As sample text, I used the first paragraph of Donald Trump’s recent rally speech in Tulsa, Oklahoma. (I figured if anything can compress well using predictive machine learning, surely Trump’s speech patterns can.)
Here’s the compressor site, with most of the input and all of the output showing:
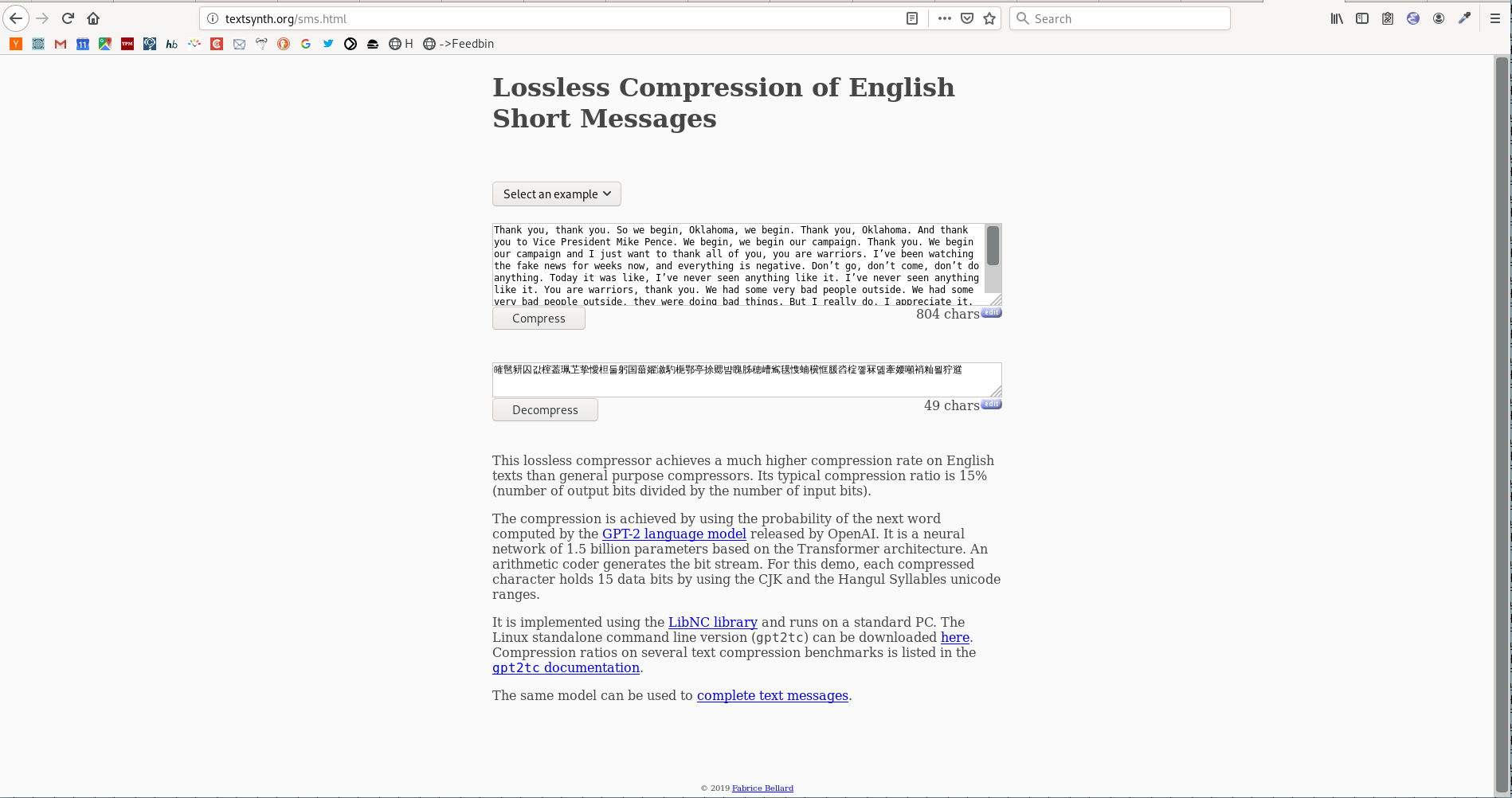
The output looks like a short string mixing Chinese and Korean because the compressed text is represented as a series of Unicode characters (encoding 15 bits of information per character — which makes the compression ratio displayed, 804/49, a bit misleading, since the characters on the bottom are twice as large as the characters on the top: 402/49 would be more more accurate, and still quite impressive).
Anyway, I naturally thought “Hmm! What would happen if I were to paste this presumably random Chinese/Korean output into Google Translate?”
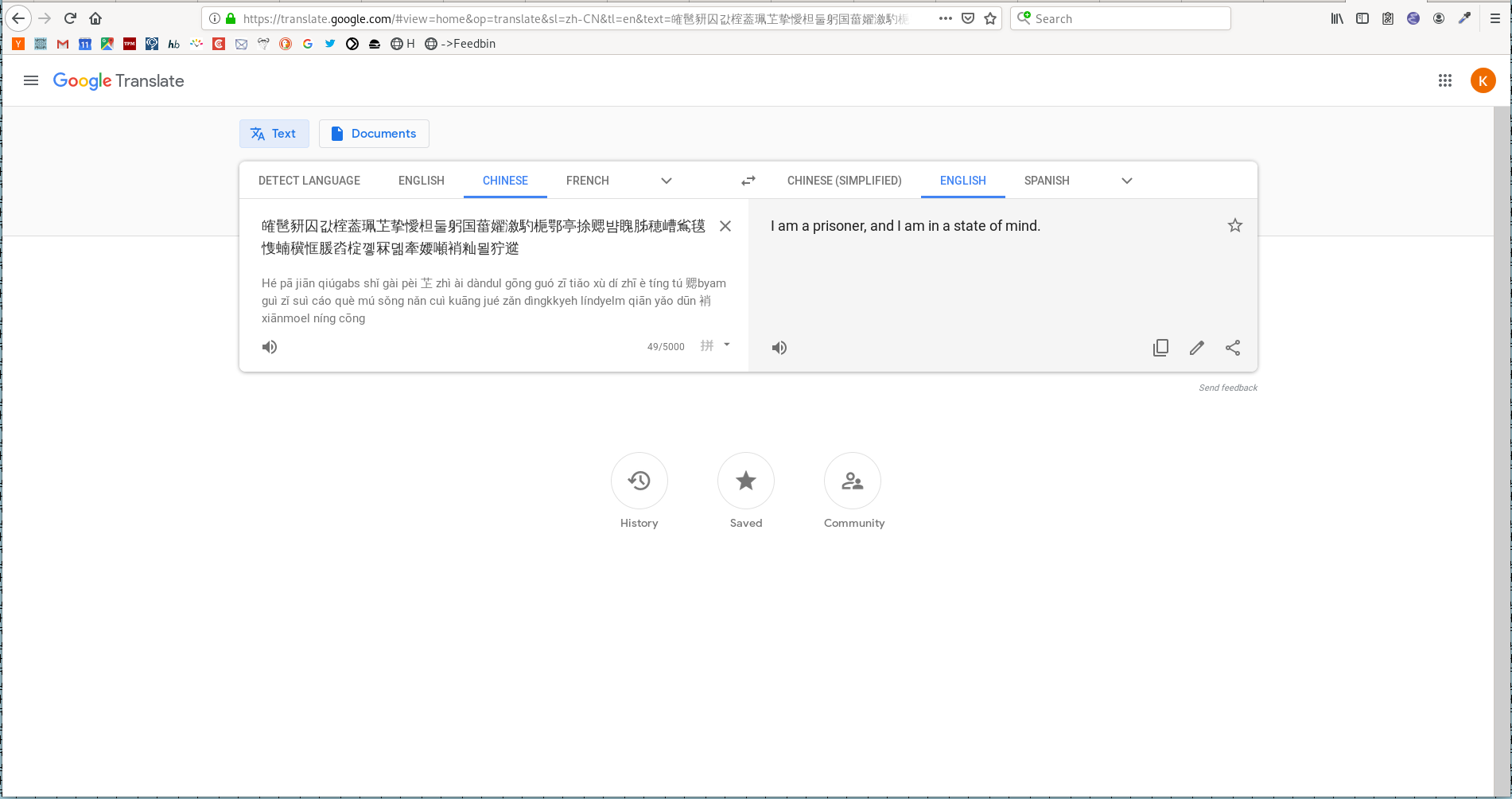
“I am a prisoner, and I am in a state of mind.”
Aren’t we all, Internet? Aren’t we all?